Matematické Fórum
Nevíte-li si rady s jakýmkoliv matematickým problémem, toto místo je pro vás jako dělané.
Nástěnka
❗22. 8. 2021 (L) Přecházíme zpět na doménu forum.matweb.cz!
❗04.11.2016 (Jel.) Čtete, prosím, před vložení dotazu, děkuji!
❗23.10.2013 (Jel.) Zkuste před zadáním dotazu použít některý z online-nástrojů, konzultovat použití můžete v sekci CAS.
Nejste přihlášen(a). Přihlásit
#1 13. 06. 2012 22:32

Rekurzívní QuickSort a počet rekurzí
Zdravím,
vyvíjím framework na platformě, která má omezení na počet rekurzí, a to na 200. Právě jsem dodělal práci s kolekcemi dat, a to včetně třídění, jenže jsem použil rekurzívní algoritmus. Na to omezení jsem přišel náhodou, zatím mi to problém na vzorcích dat nedělalo. Akorát si nejsem jist, jestli je to do budoucna takto použitelné, zda bych to spíš neměl předělat na nerekurzívní algoritmus. Moc se mi nechce, tak mě napadlo, že nejdřív zjistím počet rekurzí a zda se tomu číslu můžu přiblížit. Jenže v matice jsem nikdy moc silný nebyl, tak nevím, jak na to.
Poradíte mi někdo?
Díky, Lokutus...
Offline
#2 14. 06. 2012 10:39
Re: Rekurzívní QuickSort a počet rekurzí
Předělal bych to na nerekurzivní. Počet rekurzí se odvíjí od objemu dat a jelikož vyvíjíš framework, nemůžeš předem říci jaké aplikace na frameworku budou běžet a jak velký budou mít vstup.
Můžeš prozradit o jakou platformu se jedná?
Přímo k tomu quicksortu, nechci kecat, klidně mě opravte, ale vidím to nějak takhle:
Průběh Quicksortu se dá zaznamenat binárním stromem (máš celý vstup, rozdělí se podle pivota na 2 atd...)
V každém zpracování jednoho dílu se tedy rekurze zavolá 2x. Zaříznutí rekurze u ideálního bin. stromu log(n)
Představ si nejhorší případ, tedy že vždy vybereš pivota tak, že rozdělíš pole na 1 a n - 1 prvků... to pak bude vypadat graf takhle: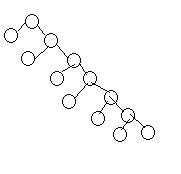
Z čehož je vidět že jeho hloubka bude n/2 což je v podstatě lineární ke vstupu. A hloubka je zaříznutí rekurze, takže v nejhorším případě můžeš srovnat max. 400 čísel pokud to bereš doslovně, asymptoticky 200.
Což moc není, záleží pro co ten framework vyvíjíš. Ale znovu říkám, mohu se plést.
Offline
#3 14. 06. 2012 13:35
Re: Rekurzívní QuickSort a počet rekurzí
↑ jindra:
Platforma je Lotus Notes, konkrétně Lotusscript. Je to dost omezený jazyk, ale zase výrazně rychlejší než build-in Java.
Normální array je tam omezen 32kB indexem, proto vyvíjím vlastní generické kolekce dat, které by měly být omezeny v podstatě jen dostupnou pamětí. Vzhledem k architektuře tam můžu počítat zhruba se sto tisíci záznamy - víc asi nemá smysl řešit. Vzhledem k řečenému soudím, že tomu přepsání algoritmu se IMO nevyhnu.
Díky za odpověď.
Offline
#4 15. 06. 2012 00:23
Re: Rekurzívní QuickSort a počet rekurzí
U quicksortu se neda matematicky odhadnout hloubka rekurze, protoze zavisi na vstupnich datech. Sice v prumernem pripade to bude cca logaritmicka hloubka, tak je i pripad, co psal jindra, kdy to bude mit linearni hloubku.
Ale treba u mergesortu uz se ta hloubka odhadnout da, tam je to vzdycky logaritmicky...
Jinak me by teda prislo nejlepsi si hlidat, jak jsi hluboko a pokud uz se budes u tech 200, tak tam na ten zbytek pustit treba nerekurzivni insert sort. Ono to je i u nekterych implementaci quicksortu udelane tak, ze na useky kratsi nez je nejaka dana hranice se pak pouzije nerekurzivni algoritmus, protoze je to rychlejsi.
Offline